Tasks module
The key and most basic requirement that Schema api aims to address is the execution of containerized software. These software translate to any Docker image on a reachable Docker image registry that can potentially accept input files, perform calculations and finally produce output files. Along with this, SCHEMA api need to facilitate the monitoring of the execution infrastructure, information regarding the executions should be recorded in a structured data store. As a result, the set of REST endpoints that allow these actions are grouped under Tasks API.
In essence, Tasks API endpoints modify a single resource: tasks. Users can submit a new task, list submitted tasks and get a submitted task's status. As mentioned in the developers' documentation index page, Schema api communicates internally with TESK, which is a TES API implementation, which specifies a set of object schemas. These object types set up a data model that can be used to satisfy the requirements of Tasks API. In fact, the data model used by the Tasks API is superset of TES object schemas. The most important of these object schemas are shown in the image below.
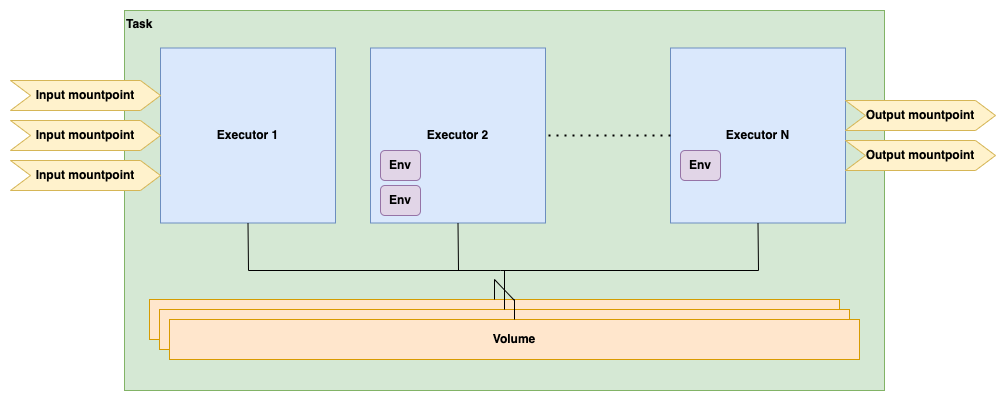
The components portrayed by the image above are the following:
- The task is the first-class citizen and acts as a parent of other components that in whole consist of the task execution configuration
- A task can have a number of executors. An executor corresponds to a single containerized job. Thus, a task can perform a complex computation based on multiple Docker images.
- Each executor can have a set of environment variables; these are environment variables on the executor's container.
- Each task can have a number of input and output mount points. These are mappings of files or directories from a reachable file system to the container and vice versa. Input mount points move files into the container of the first executor, while output mount points pull files from the container of the last executor.
- Each task can also have a set of volumes. Volumes can be thought as shared directories accessible by all executors. Executors can write output data on these volumes, which can be used as input data by other executors, later in task's execution pipeline.
The use of multiple executors, mount points and volumes allows for the definition of an imperative workflow.
Apart from the components described above, TES API also defines the following object schemas:
- A Resources definition which acts as a resource claim for the execution of a task
- Tags which can be assigned to tasks